Support Multiple LLM Runtimes
11 months ago by Ping-Lin Chang
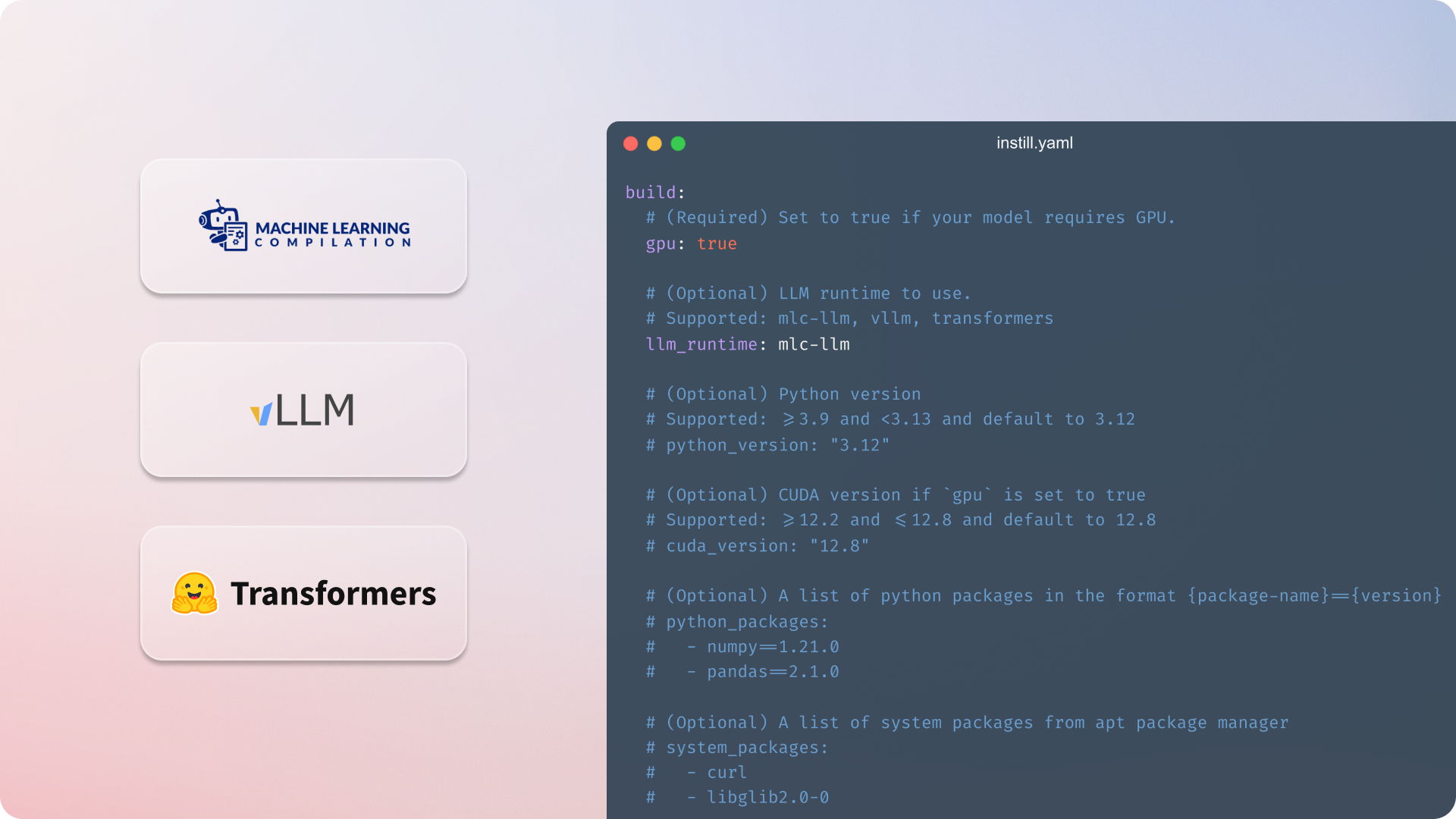
Instill Core now supports multiple LLM runtimes, including MLC LLM , vLLM and Transformers — giving you more flexibility to run fast, efficient, and scalable LLMs on your preferred runtime engine.
What’s new:
You can now specify the desired LLM runtime in your model’s instill.yaml:
build:
# (Required) Set to true if your model requires GPU.
gpu: true
# (Optional) LLM runtime to use.
# Supported mlc-llm, vllm, transformers
llm_runtime: vllmOnce defined, and paired with the corresponding model implementation, run instill build to containerize your model and instill push to deploy the model in Instill Core.
For full details on model building, see the documentation.
Whether you’re optimizing for performance, cost, or deployment footprint, Instill Core now empowers you to serve LLMs your way.